CodeGeeX: A Multilingual Code Generation Model
Sep. 19, 2022 | Language:中文

🏠 Homepage | 💻 Code | 🪧 DEMO | 🛠 VS Code Extension | 🤖 Download Model | 📃 Paper(Coming soon!)
We introduce CodeGeeX, a large-scale multilingual code generation model with 13 billion parameters, pre-trained on a large code corpus of more than 20 programming languages. As of June 22, 2022, CodeGeeX has been trained on more than 850 billion tokens on a cluster of 1,536 Ascend 910 AI Processors. CodeGeeX has several unique features:
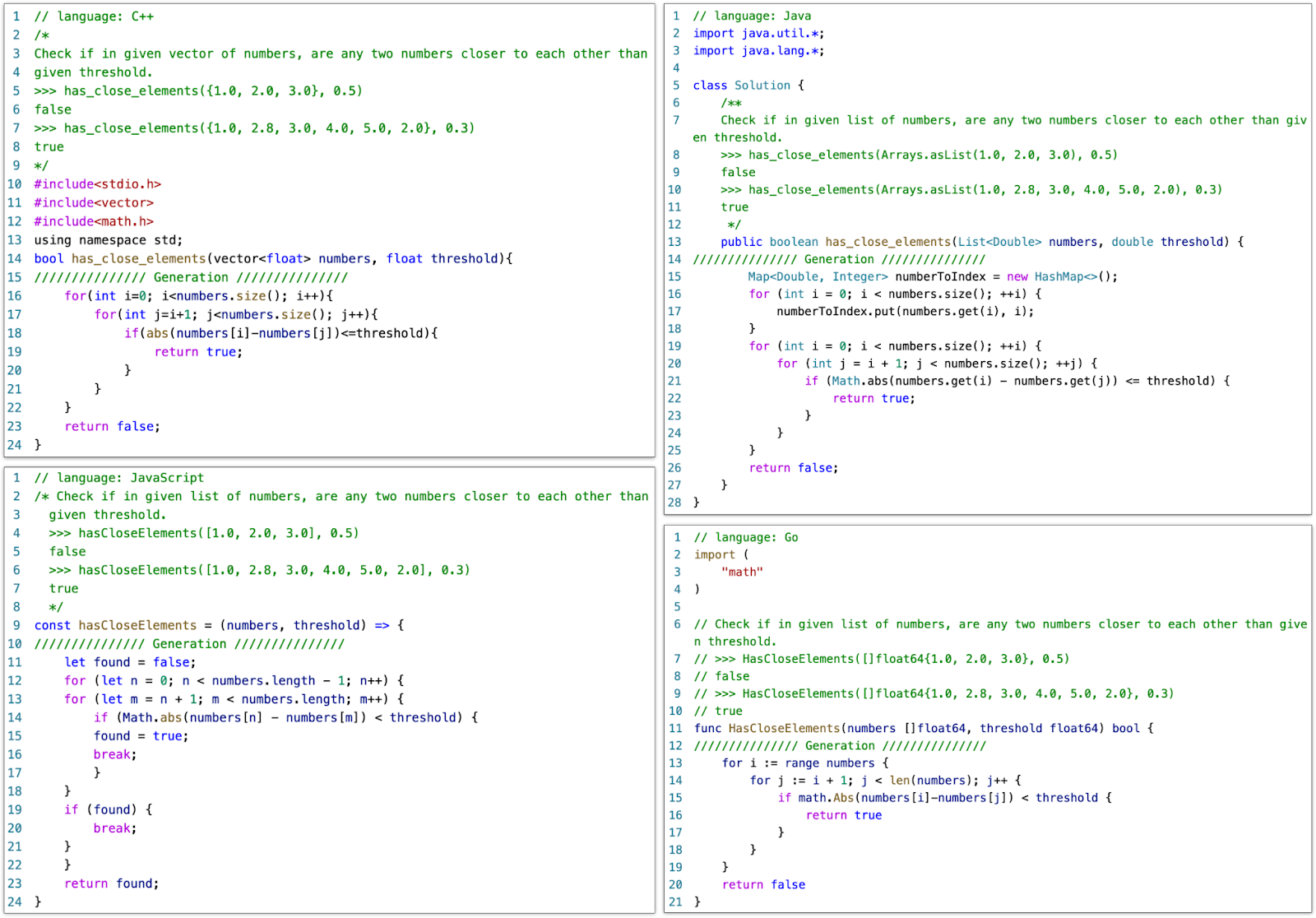
- Multilingual Code Generation: CodeGeeX has good performance for generating executable programs in several mainstream programming languages, including Python, C++, Java, JavaScript, Go, etc. DEMO
- Crosslingual Code Translation: CodeGeeX supports the translation of code snippets between different languages. Simply by one click, CodeGeeX can transform a program into any expected language with a high accuracy. DEMO
- Customizable Programming Assistant: CodeGeeX is available in the VS Code extension marketplace for free. It supports code completion, explanation, summarization and more, which empower users with a better coding experience. VS Code Extension
- Open-Source and Cross-Platform: All codes and model weights are publicly available for research purposes. CodeGeeX supports both Ascend and NVIDIA platforms. It supports inference in a single Ascend 910, NVIDIA V100 or A100. Apply Model Weights
HumanEval-X for Realistic Multilingual Benchmarking. To help standardize the evaluation of multilingual code generation and translation, we develop and release the HumanEval-X Benchmark. HumanEval-X is a new multilingual benchmark that contains 820 human-crafted coding problems in 5 programming languages (Python, C++, Java, JavaScript, and Go), each of these problems is associated with tests and solutions. Usage
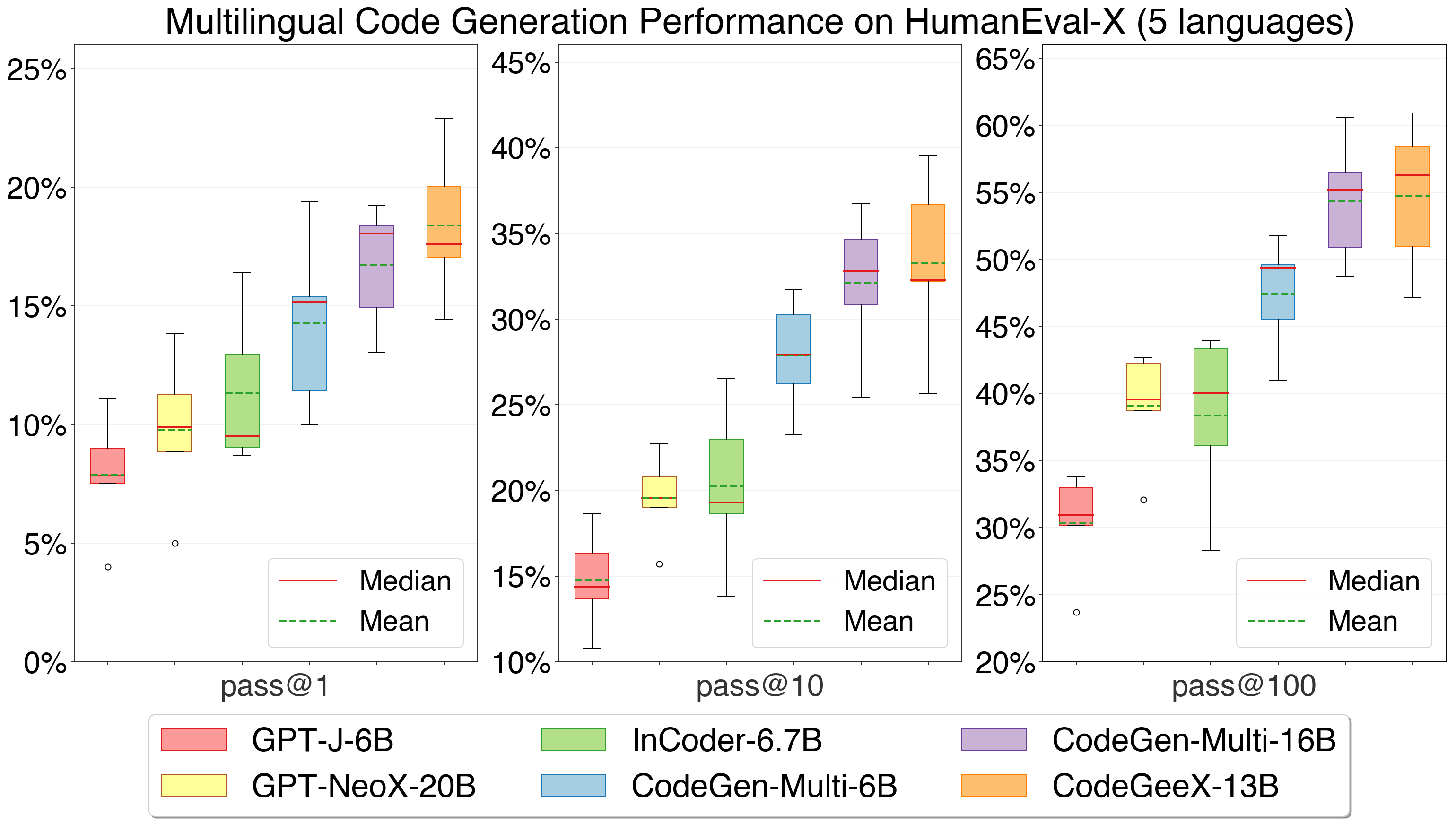
CodeGeeX achieves the highest average performance compared with other open-sourced multilingual baselines.
Background: Program Synthesis with Pre-Trained Language Models
Large-scale pre-trained models trained on code corpora have achieved impressive results. Codex[1] demonstrates the potential of pre-trained models by solving introductory programming problems in Python. Since then, various models trained with multiple programming languages have also been introduced, including AlphaCode[2], CodeGen[3], InCoder[4], PolyCoder[5], and PaLMCoder[6]. Although trained with multiple languages, most of these models are only evaluated for their correctness in Python, making it unclear about their (overall) performance in other programming languages.
Existing public program synthesis benchmarks focus on two major types of metrics: string similarity in multilingual cases and functional correctness only in Python. The first type includes multilingual benchmarks like CodeXGLUE[7] and XLCoST[8], covering tasks including code completion, code translation and code summarization. The limit is that they only adopt string similarity metrics like BLEU[9] and CodeBLEU[10], which are poor indicators for telling whether the generated program is correct. The second type instead tests the functional correctness of codes using test cases, including HumanEval[1:1], MBPP[11] and APPS[12]. However, they are only in Python, without supporting other languages. The lack of realistic multilingual benchmarks for evaluating functional correctness has thus far delayed the progress of multilingual program synthesis.
CodeGeeX: A Multilingual Code Generation Model
Architecture: CodeGeeX is a large-scale pre-trained programming language model based on transformers. It is a left-to-right autoregressive decoder, which takes code and natural language as input and predicts the probability of the next token. CodeGeeX contains 40 transformer layers with a hidden size of 5,120 for self-attention blocks and 20,480 for feed-forward layers, making its size reach 13 billion parameters. It supports a maximum sequence length of 2,048.
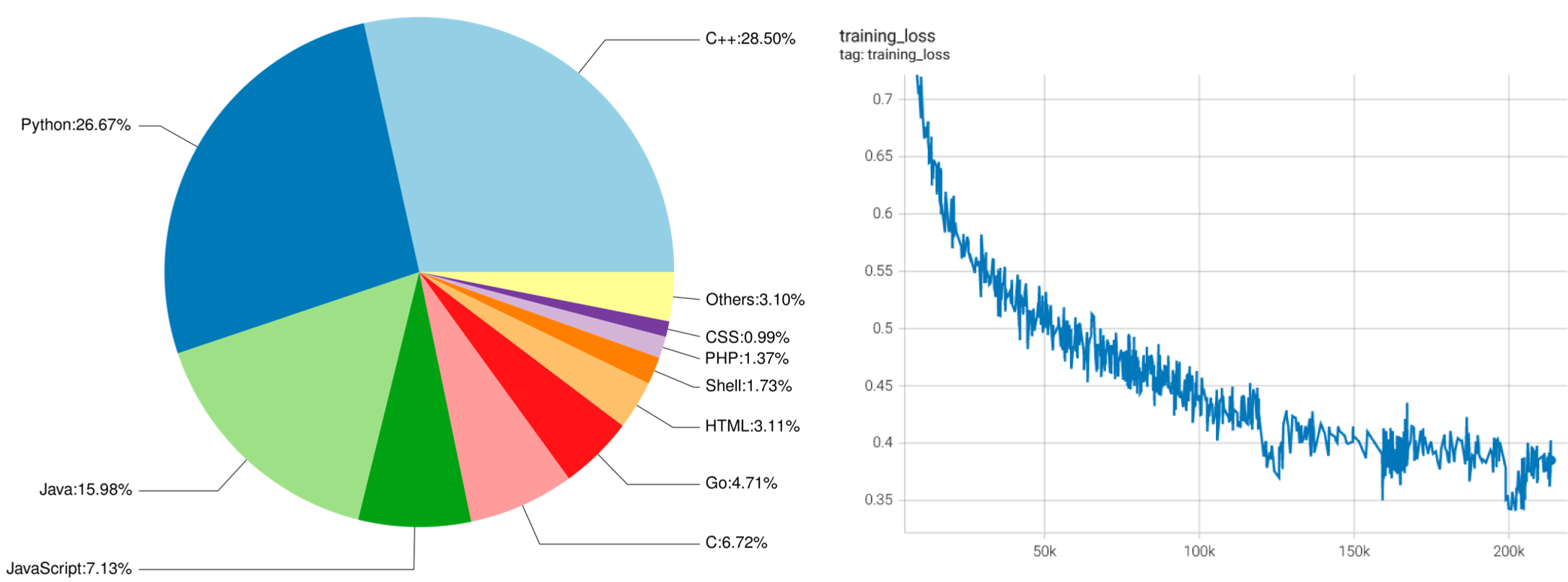
Left: the proportion of programming languages in CodeGeeX's training data. Right: the plot of training loss against the training steps of CodeGeeX.
Code Corpus: Our training data contains two parts. The first part is from open-sourced code datasets, The Pile[13] and CodeParrot. The Pile contains a subset of code corpus that collects public repositories with more than 100 stars from GitHub, from which we select codes in 23 popular programming languages. The second part is supplementary data directly scrapped from the public GitHub repositories that do not appear in previous datasets, including Python, Java and C++. To obtain data of potentially higher quality, repositories with at least one star and its size smaller than 10MB are chosen. A file is filtered out if it 1) has more than 100 characters per line on average, 2) is automatically generated, 3) has a ratio of alphabet less than 40%, or 4) is bigger than 100KB or smaller than 1KB. To help the model distinguish different languages, we add a language-specific prefix at the beginning of each segment in the form of [Comment sign] language: [LANG], e.g., # language: Python. For tokenization, we use the same tokenizer as GPT-2[14] and process whitespaces as extra tokens, resulting in a vocabulary of 50,400 tokens. In total, the code corpus has 23 programming languages with 158.7B tokens.
Training: We implement CodeGeeX in Mindspore 1.7 and train it on 1,536 Ascend 910 AI Processor (32GB). The model weights are under FP16 format, except that we use FP32 for layer-norm and softmax for higher precision and stability. The entire model consumes about 27GB of memory. To increase the training efficiency, we adopt an 8-way model parallel training together with 192-way data parallel training, with ZeRO-2 optimizer[15] enabled. The micro-batch size is 16 and the global batch size reaches 3,072. Moreover, we adopt techniques to further boost the training efficiency including the element-wise operator fusion, fast gelu activation, matrix multiplication dimension optimization, etc. The entire training process takes nearly two months, spanning from April 18 to June 22, 2022, during which 850B tokens were passed for training, i.e., 5+ epochs. In addition to the support on the Ascend platform, we have been also working on adapting the model to other GPU platforms, which will be ready soon.
HumanEval-X: A Realistic Benchmark for Multilingual Program Synthesis
To better evaluate the multilingual ability of code generation models, we propose a new benchmark HumanEval-X. While previous works evaluate multilingual program synthesis under semantic similarity (e.g., CodeBLEU[10:1]) which is often misleading, HumanEval-X evaluates the functional correctness of the generated programs. HumanEval-X consists of 820 high-quality human-crafted data samples (each with test cases) in Python, C++, Java, JavaScript, and Go, and can be used for various tasks.

An illustration of tasks supported by HumanEval-X. Declarations, docstrings, and solutions are marked with red, green, and blue respectively. Code generation uses declaration and docstring as input, to generate solution. Code translation uses declaration in both languages and translate the solution in source language to the one in target language.
In HumanEval-X, every sample in each language contains declaration, docstring, and solution, which can be combined in various ways to support different downstream tasks including generation, translation, summarization, etc. We currently focus on two tasks: code generation and code translation. For code generation, the model uses declaration and docstring as input to generate the solution. For code translation, the model uses declarations in both languages and the solution in the source language as input, to generate solutions in the target language. We remove the description during code translation to prevent the model from directly solving the problem. For both tasks, we use the unbiased pass@k metric proposed in Codex[1:2].
Multilingual Code Generation
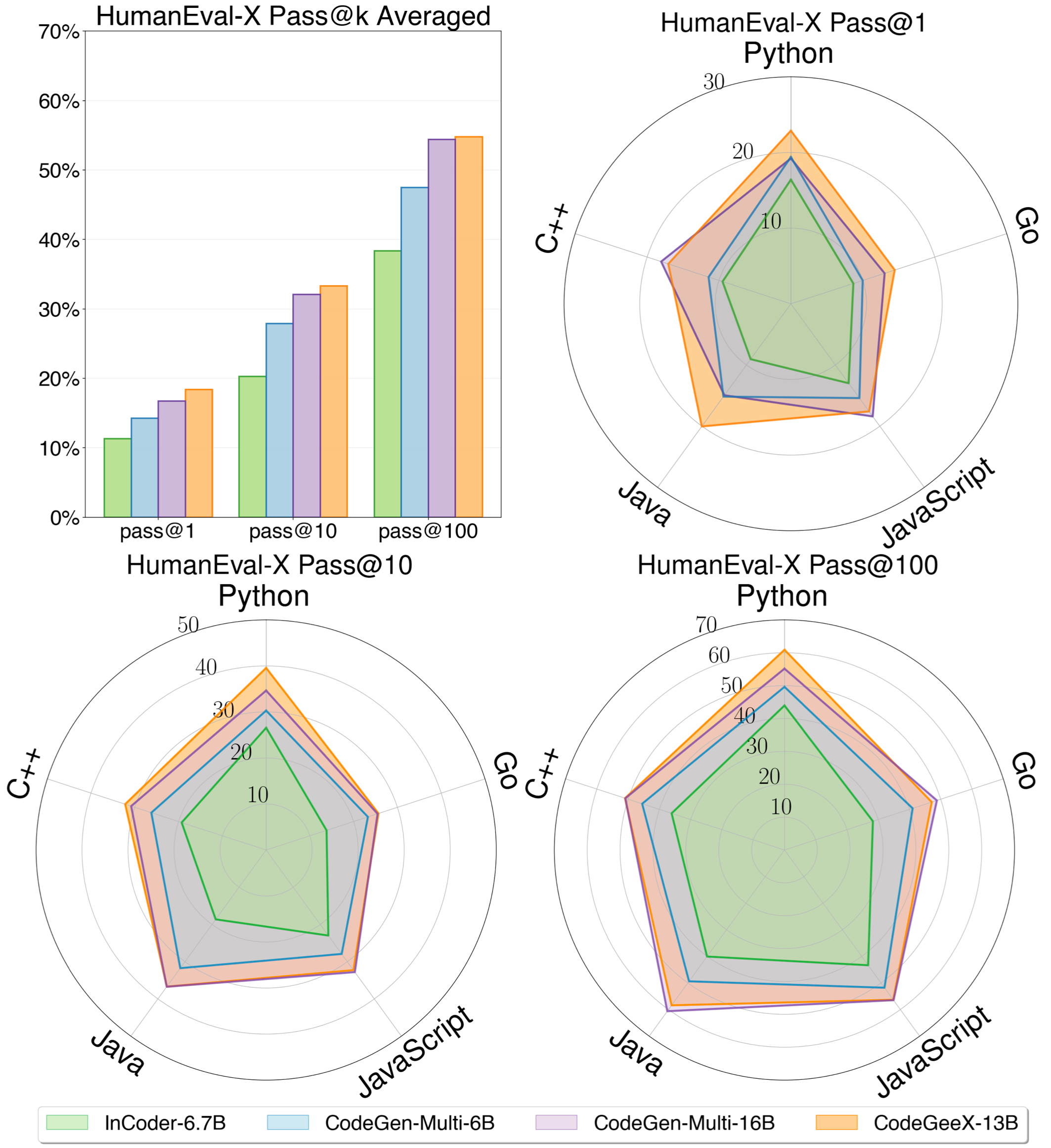
Upper-left: the average performance of all languages of each model on code generation task of HumanEval-X. Others: the detailed pass@k (k=1,10,100) performance for five languages. CodeGeeX achieves the highest average performance compared with InCoder-6.7B, CodeGen-Multi-6B and CodeGen-Multi-16B.
We compare CodeGeeX with two other open-sourced code generation models, InCoder (from Meta) and CodeGen (from Salesforce). Specifically, InCoder-6.7B, CodeGen-Multi-6B and CodeGen-Multi-16B are considered. CodeGeeX significantly outperforms models with smaller scales (by 7.5%~16.3%) and is competitive with CodeGen-Multi-16B with a larger scale (average performance 54.76% vs. 54.39%). CodeGeeX achieves the best average performance across languages.
Multilingual Gen. Beats the Best Monolingual One
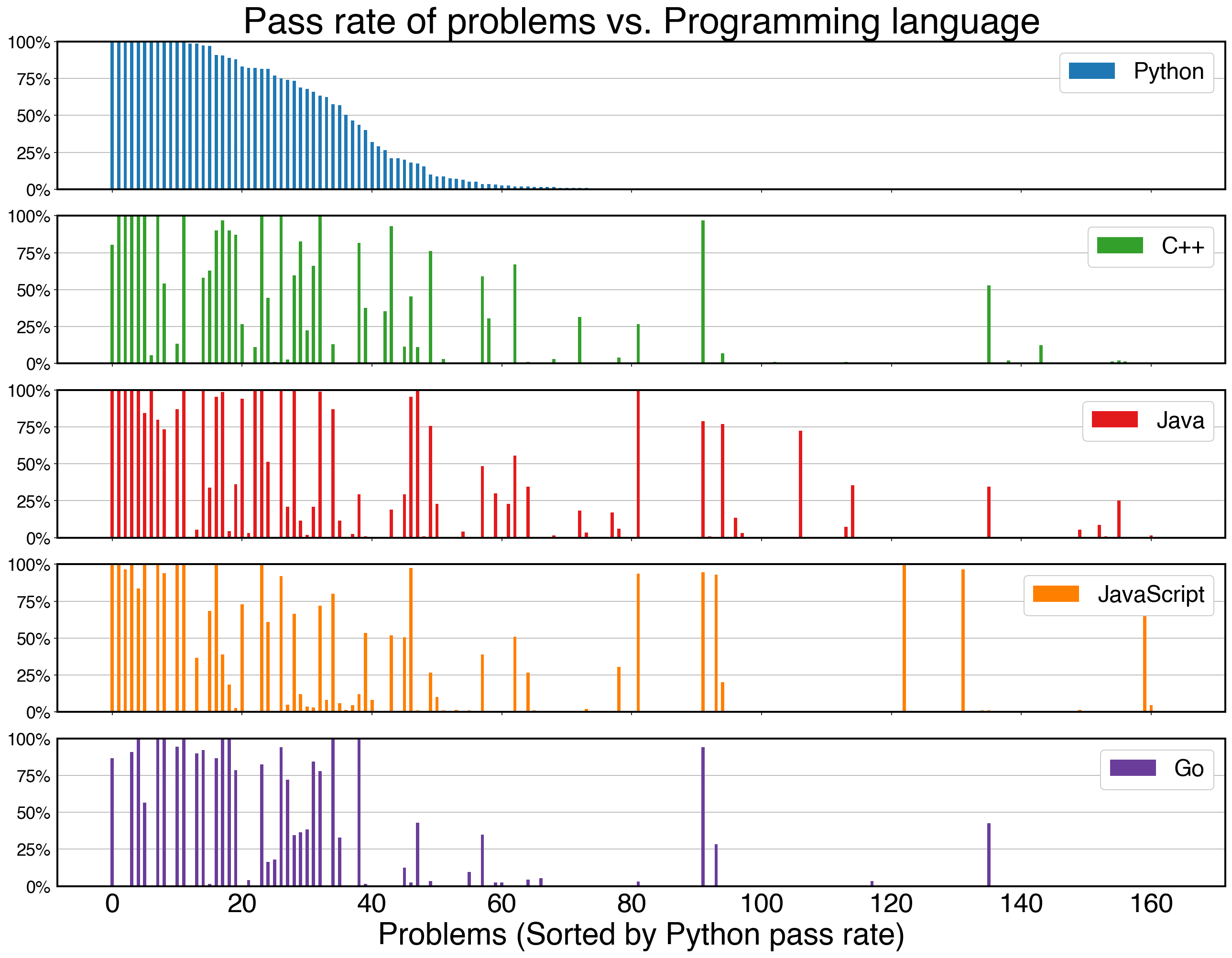
In HumanEval-X, each problem's pass rate varies when generating in different programming languages with CodeGeeX.
When looking into the detailed pass rate of each problem, we find that some of them can be better solved using a specific language. This phenomenon inspires us to distribute the generation budget in multiple languages to help improve the diversity of the generated samples, thus increasing the chance of generating at least 1 correct answer.

Results for fixed-budget multilingual generation on HumanEval-X. Best model-wise performance on methods are bolded, while best method-wise performance for models are in italic.
A uniform assignment, e.g., distributing 100 samples to 20*5, can already improve the pass rate by a solid margin. Another heuristic that allocates generation budgets by the proportion of languages in the training corpus is even better, improving the pass@100 of CodeGeeX from 60.92% to 62.95%. All multilingual models benefit from this heuristic, with pass@100 improved by 1~3% against the best single language. CodeGeeX achieves higher performance than baseline models under the above budget-distributed settings.
Crosslingual Code Translation
![]()
Results on HumanEval-X code translation task. Best language-wise performance are bolded.
We also evaluate the performance of translation across different programming languages. We test the zero-shot performance of CodeGeeX, as well as the fine-tuned CodeGeeX-13B-FT (fine-tuned using the training set of code translation tasks in XLCoST[8:1]; Go is absent in the original set, we thus add a small set to it). The results indicate that models have a preference for languages, e.g., CodeGeeX is good at translating other languages to Python and C++, while CodeGen-Multi-16B is better at translating to JavaScript and Go; these could probably be due to the difference in language distribution in the training corpus. Among 20 translation pairs, we also observe that the performance of A-to-B and B-to-A are always negatively correlated, which might indicate that the current models are still not capable of learning all languages well.
Online Demos
We have developed two online demos for both code generation and code translation tasks. Welcome to have a try!
A Programming Assistant on VS Code
Based on CodeGeeX, we develop a VS Code extension (search 'CodeGeeX' in the Extension Marketplace) that assists the programming of different programming languages. Besides the multilingual code generation/translation abilities, we turn CodeGeeX into a custom programming assistant using its few-shot ability. It means that when a few examples are provided as extra prompts in the input, CodeGeeX will imitate what are done by these examples and generate codes accordingly. Some cool features can be implemented using this ability, like code explanation, summarization, generation with specific coding style, and more. For example, one can add code snippets with his/her own coding style, and CodeGeeX will generate codes in a similar way. You can also try prompts with specific formats to inspire CodeGeeX for new skills, e.g., explain codes line by line. Have a try on customizing your programming assistant!
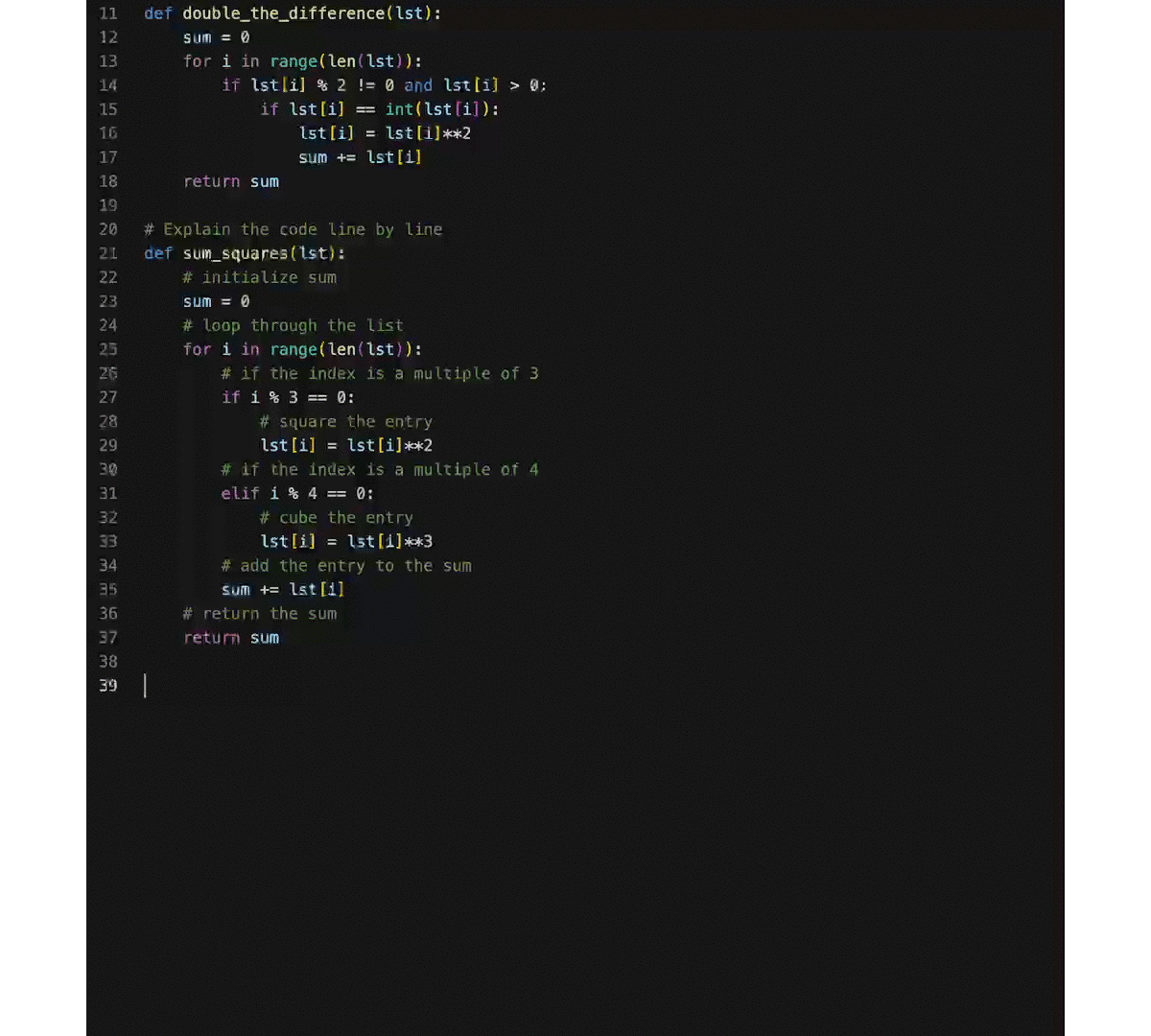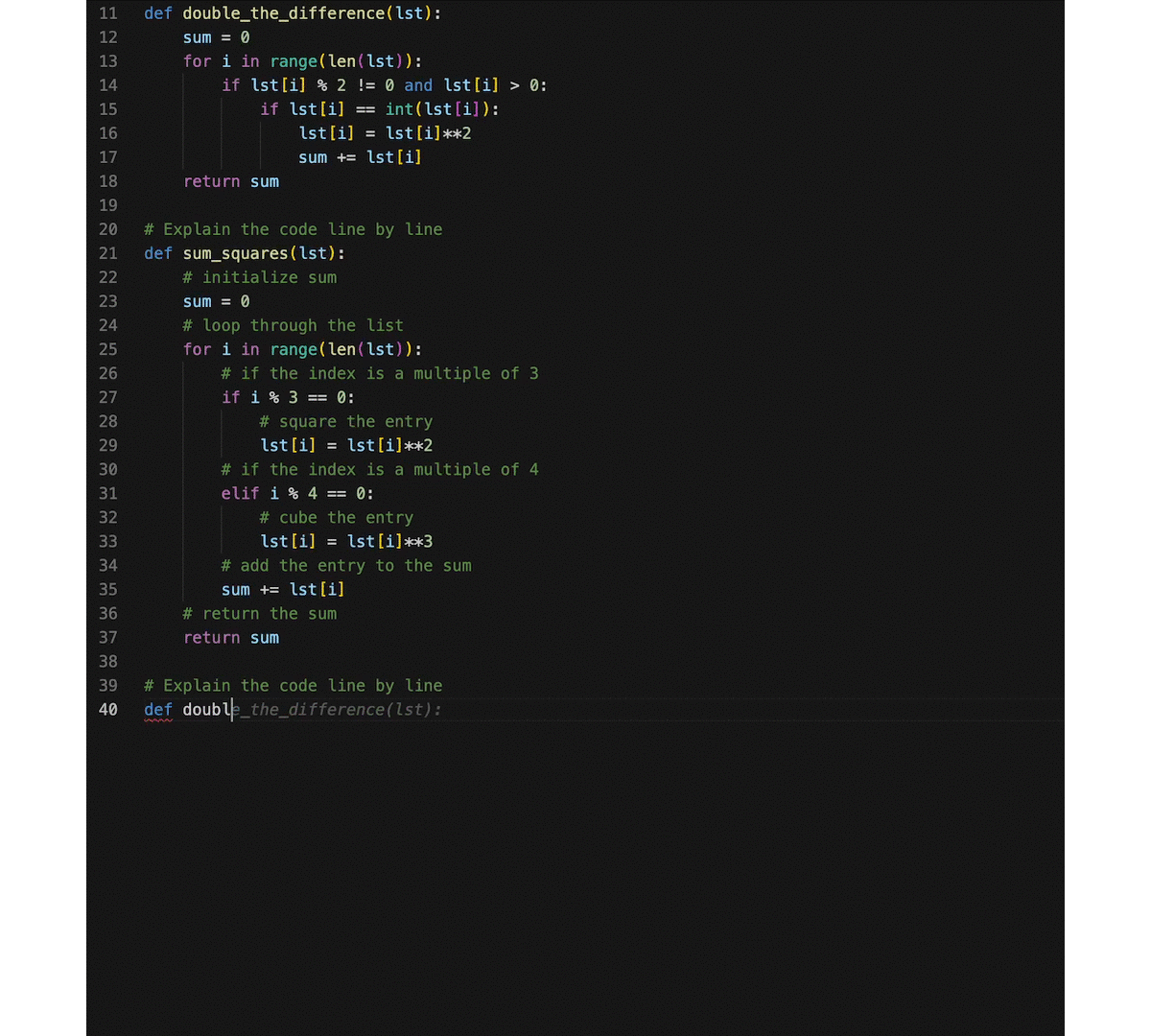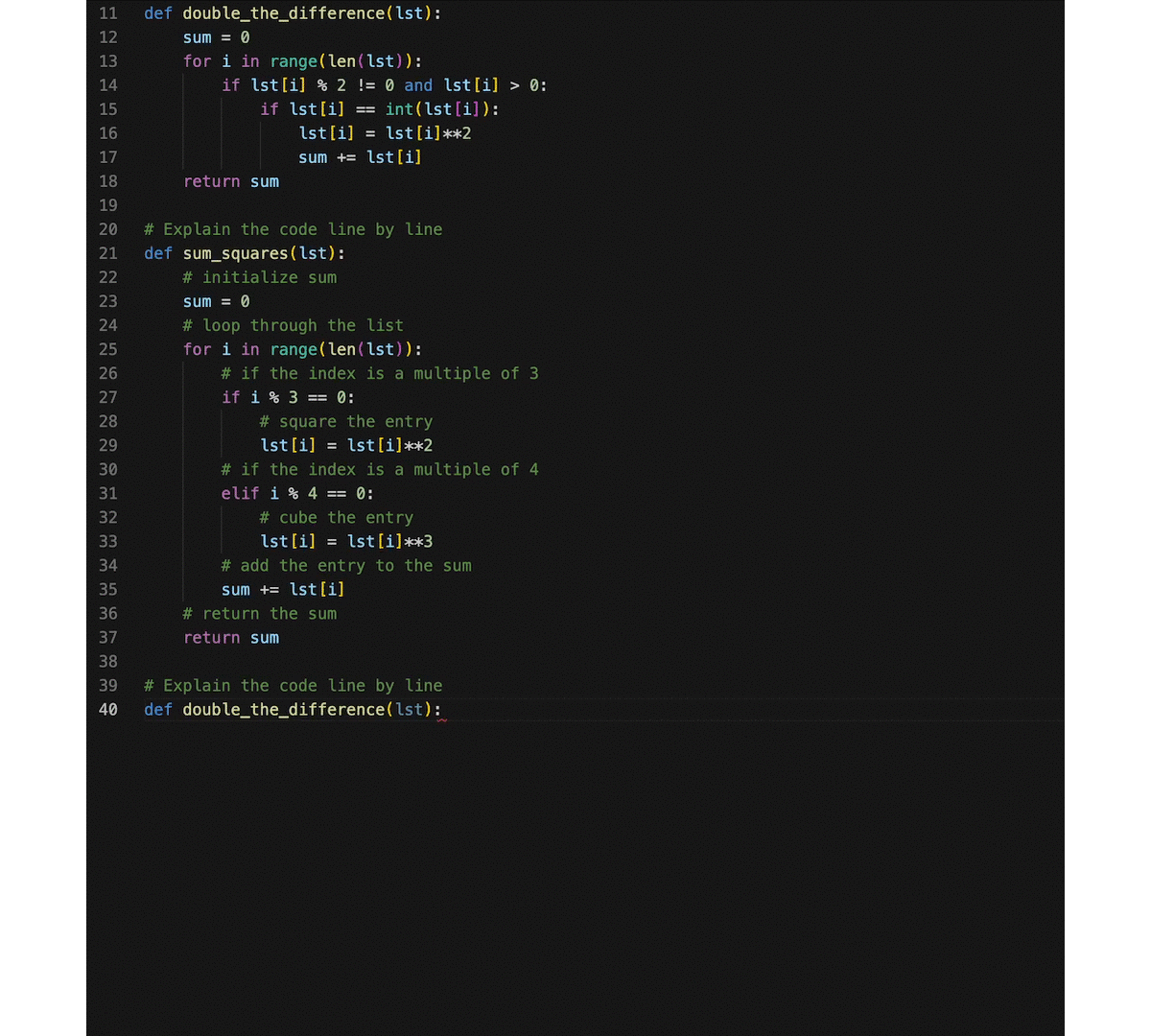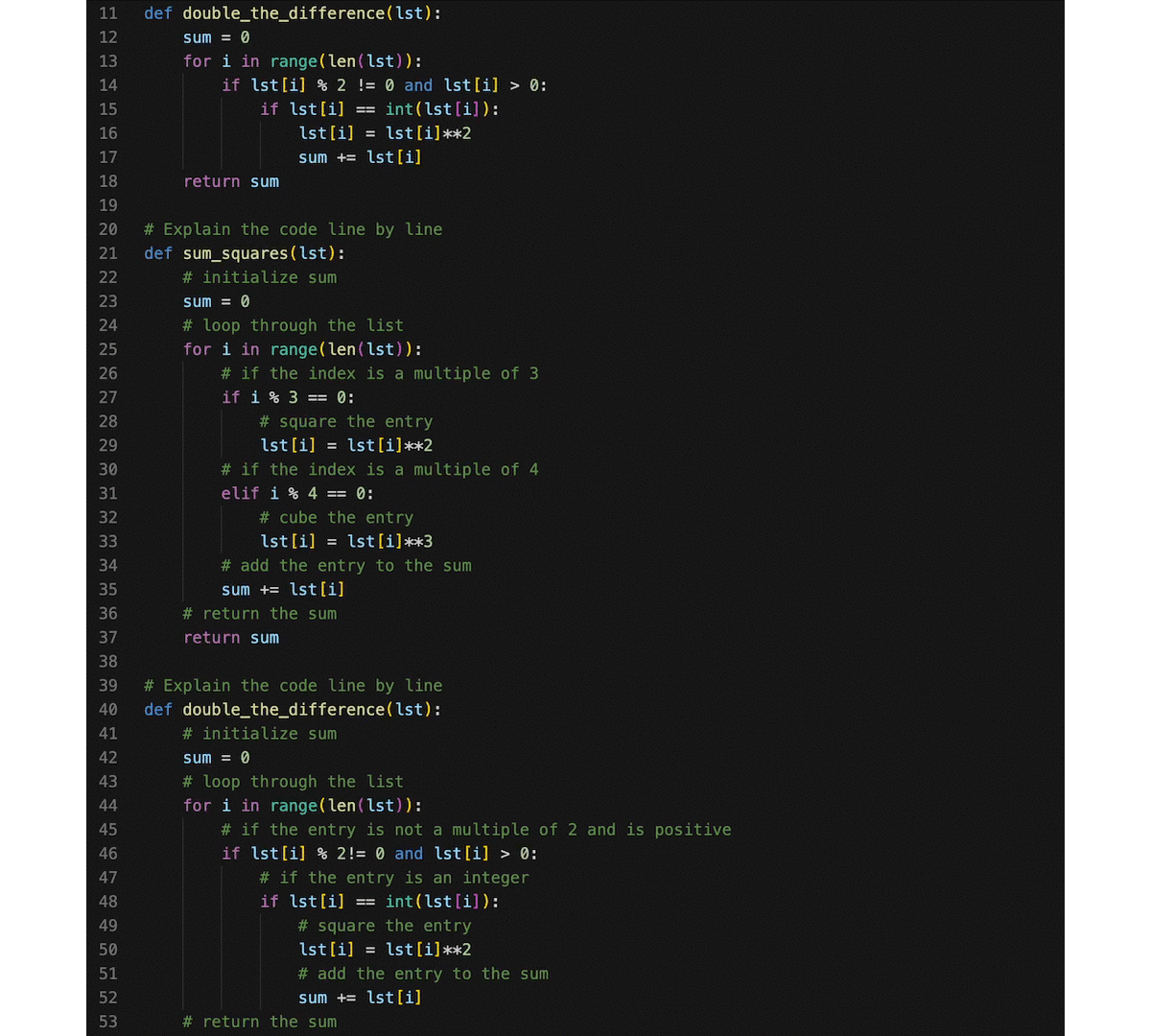
In the above example, we provide additional prompts in the input that explains a function code line by line, then CodeGeeX will learn to explain an existing code snippet accordingly. More features can be implemented in a similar way by providing other hand-crafted prompts.
Discussions and Future Works
Following previous works, CodeGeeX again proves the power of large pre-trained models in program synthesis. The multilingual ability of CodeGeeX further shows the potential of solving problems with a ubiquitous set of formalized languages. However, this is just the first step. Many questions still need to be investigated in the future, three of which are listed here.
First, we find that the model capacity is essential for its multilingual ability. It is not trivial for the model to benefit from learning multiple programming languages. Human programmers can abstract the high-level concept of programming, thus learning one or two languages can help them master other languages. On the contrary, the model still needs a large parameter size to concurrently store the knowledge of each language (e.g., PaLMCoder with 540B parameters suggests that an extremely-large model capacity can offer amazing performance). How to help the model extract the most essential and common knowledge of programming remains a fundamental challenge.
Second, CodeGeeX shows a kind of reasoning ability but is not general for all langauges. We demonstrate that CodeGeeX can indeed solve problems in different languages. However, the pass rate distribution varies a lot among languages. Even though the model has already “mastered” the grammar of these languages very well, it is not able to solve the same problem using different languages. We assume that it could probably be related to some language-specific features (e.g., some problems are easier to solve in Python), or it could be simply due to the appearance of a similar language-specific implementation in training data. Either case, there is a long way to go for the model to have reliable reasoning ability.
Third, the few-shot ability of CodeGeeX requires further exploration. Instead of using costly fine-tuning approaches, we can provide a few examples to inspire the model to generate the desired programs. Recent works like the chain-of-thought prompting[16] have already shown impressive results using this approach, which largely motivates us to adapt it to CodeGeeX. It is also the principe behind our customizable programming assistant, and we welcome programmers and researchers to further explore ways to using CodeGeeX.
Please kindly let us know if you have any comment or suggestion, via codegeex@aminer.cn.
Acknowledgement
This project is supported by the National Science Foundation for Distinguished Young Scholars (No. 61825602).
Lead Contributors
Qinkai Zheng (Tsinghua KEG), Xiao Xia (Tsinghua KEG), Xu Zou (Tsinghua KEG)
Contributors
Tsinghua KEG—The Knowledge Engineering Group at Tsinghua: Aohan Zeng, Wendi Zheng, Lilong Xue
Zhilin Yang's Group at Tsinghua IIIS: Yifeng Liu, Yanru Chen, Yichen Xu (BUPT, work was done when visiting Tsinghua)
Peng Cheng Laboratory: Qingyu Chen, Zhongqi Li, Gaojun Fan
Zhipu.AI: Yufei Xue, Shan Wang, Jiecai Shan, Haohan Jiang, Lu Liu, Xuan Xue, Peng Zhang
The Ascend and Mindspore Team: Yifan Yao, Teng Su, Qihui Deng, Bin Zhou
Data Annotations
Ruijie Cheng (Tsinghua), Peinan Yu (Tsinghua), Jingyao Zhang (Zhipu.AI), Bowen Huang (Zhipu.AI), Zhaoyu Wang (Zhipu.AI)
Advisors
Zhilin Yang (Tsinghua IIIS), Yuxiao Dong (Tsinghua KEG), Wenguang Chen (Tsinghua PACMAN), Jie Tang (Tsinghua KEG)
Computation Sponsors
Peng Cheng Laboratory
Zhipu.AI—an AI startup that aims to teach machines to think like humans
Project Leader
Jie Tang (Tsinghua KEG & BAAI)
References
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021. ↩︎ ↩︎ ↩︎
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode. arXiv preprint arXiv:2203.07814, 2022. ↩︎
Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. A conversational paradigm for program synthesis. arXiv preprint arXiv:2203.13474, 2022. ↩︎
Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Wen-tau Yih, Luke Zettlemoyer, and Mike Lewis. InCoder: A generative model for code infilling and synthesis. arXiv preprint arXiv:2204.05999, 2022. ↩︎
Frank F Xu, Uri Alon, Graham Neubig, and Vincent Josua Hellendoorn. A systematic evaluation of large language models of code. In Proceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming, pp. 1–10, 2022. ↩︎
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, and et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022. ↩︎
Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin Clement, Dawn Drain, Daxin Jiang, Duyu Tang, et al. 2021. Codexglue: A machine learning benchmark dataset for code understanding and generation. arXiv preprint arXiv:2102.04664. ↩︎
Ming Zhu, Aneesh Jain, Karthik Suresh, Roshan Ravindran, Sindhu Tipirneni, and Chandan K Reddy. 2022. XLCoST: A benchmark dataset for cross-lingual code intelligence. arXiv preprint arXiv:2206.08474 ↩︎ ↩︎
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318. ↩︎
Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. Codebleu: a method for automatic evaluation of code synthesis. arXiv preprint arXiv:2009.10297. ↩︎ ↩︎
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models. arXiv preprint arXiv:2108.07732. ↩︎
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, et al. 2021. Measuring coding challenge competence with apps. arXiv preprint arXiv:2105.09938. ↩︎
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020. ↩︎
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre training. 2018. ↩︎
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. ZeRO: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 1–16. IEEE, 2020. ↩︎
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903, 2022. ↩︎