mGLM-1B 是一个开源开放的多语言(支持101种不同语言)预训练模型。模型基于通用语言模型(GLM1)架构,拥有约10亿参数。mGLM-1B的训练语料由101种不同语言的纯文本数据构成,模型在10台A100(80G*8)服务器上训练了共约8000亿个词例,预训练后的mGLM-1B多语言模型具有以下优势:
- 支持多种语言: 最多支持101种不同的语言;
- 支持跨语言生成: 支持跨语言的I/O任务,例如翻译、跨语言摘要和跨语言生成标题等;
- 跨语言零样本学习: 支持在多种语言之间迁移学到的知识,缓解小语种语料缺乏的问题;
- 跨领域零样本学习: 支持在不同领域之间迁移学到的共性知识;
- 接近SOTA表现: mGLM-1B模型在多个任务上逼近或超过mT52等SOTA模型的表现;
- 开源可复现: 相关代码和模型文件已开源,可供下载使用。
模型文件、预训练、微调和推理代码已经在我们的Github仓库公开,相关论文即将发布。
mGLM-1B: 构建
早在2022年年初,我们便开始计划训练一个与GLM架构相同的大型多语言模型。我们期望这类多语言模型可以拥有很好的 跨语言 和 零样本学习 的能力。为此,我们收集了大量的纯文本多语言数据,并以此训练了一个10亿参数的多语言GLM模型,取名为mGLM-1B。在预训练之前,我们对收集到的混合语料进行了分析和预处理,并重新调整了其中各个语言的分布比例。新的比例依照现实世界的理想语言分布构成,以确保混合语料的有效性。
多语言预训练语料
我们的多语言预训练语料收集自互联网,总大小约为25TB。我们使用语言检测工具将这些语料归类为101种不同的语言,但我们随后便发现,这些语言的样本分布比例并不理想。例如,混合语料中的英语样本太多,以至于多语言模型可能会在小语种上欠拟合,从而表现不佳。混合语料中各语言样本的对数分布如图2所示。
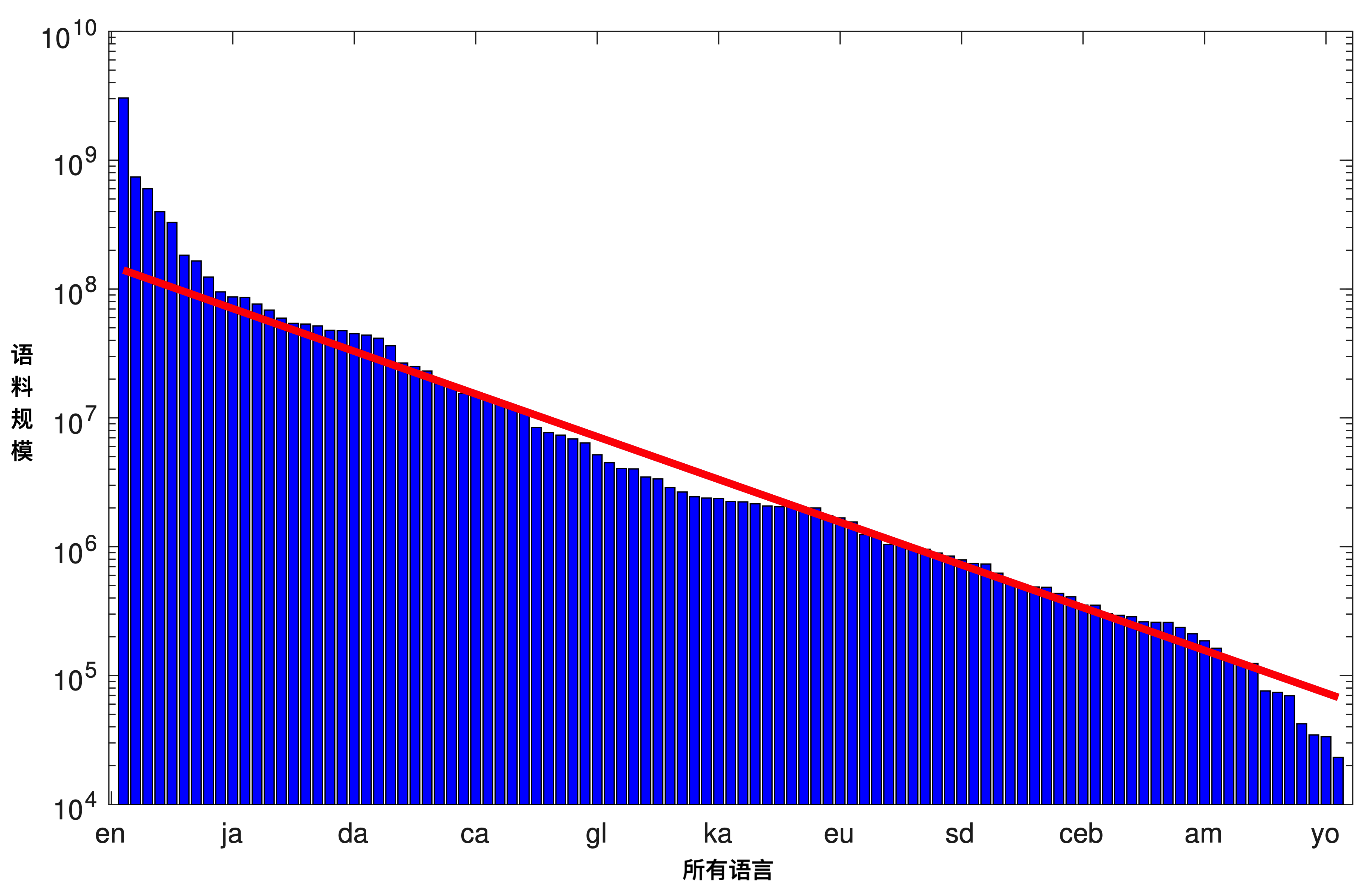
如果我们假设现实世界的语言使用率分布与 词频分布 或 学者论文数量分布 类似,是某个幂指数级别的分布。图2的对数分布图显示,我们收集的语料与理想的对数线性曲线(红线表示)之间有一定误差。我们认为这类误差传递到训练结果上,很可能会造成模型在小语种上欠拟合。因此我们选择在对数分布空间上拟合一条直线来代表理想的语言使用率(语料采样)的分布,并对那些不符合理想分布的语言(主要是高频和低频语言)做采样调整(升采样或降采样)。结果显示,在这一步中,如英语、俄语、西班牙语、法语、意大利语等高频语言都被执行了相当程度的降采样。
传统的多语言模型在预训练之前,还会对所有语言统一按某种比例做进一步的降采样,来避免模型在高频语言上过拟合。其中被广泛使用的一种降采样策略,是将降采样比例设定为与语言规模成正相关,即:$P\left( L\right) \propto \left| L\right| ^{\alpha }$。XLM-R3和mT52的研究都指出,该策略下最优的方案是将超参数 $\alpha$ 设定为 0.3。在构建mGLM-1B的预训练语料时,我们选择了一种 两阶段语料重构 的方式,即:1. 首先采用拟合对数线性分布的方式对语料做第一步的升/降采样;2. 接着根据XLM-R3和mT52的研究,将所有语料统一做$P\left( L\right) \propto \left| L\right| ^{0.3}$的按比例降采样,需要指出的是,这种降采样并不会改变语言在对数坐标系中的分布类型,其在对数坐标系中依然呈线性(只是斜率更小)。我们认为这种方式可以保证不同来源和分布的语料都能调整到统一的最优分布。
模型构建
mGLM-1B基于一个大小约为25万的多语言词表而构建。 为了与同规模的mT52相比较,我们将hidden size设置为1536,模型层数设置为24,head数设置为16。我们将最大序列长度设置为512,并在每个batch训练2560条数据。模型在 64张NVIDIA Tesla A100 80GB GPU 上预训练了约 60万 个批次的数据。
基于上述配置,我们可以计算得知:mGLM-1B的参数量约在10亿左右(1.06b),其预训练的词例数量约为8000亿。这两项数据都与同规模的\(mT5_{Large}\)2相当(\(mT5_{Large}\)约含有1.2b参数并训练了约1万亿词例)。
mGLM-1B: 任务表现
在预训练结束之后,我们对mGLM-1B和其它多语言模型进行了一系列有说服力的下游任务测试。结果显示,mGLM-1B和其它同规模的多语言模型(包括同规模的SOTA模型\(mT5_{Large}\))相比具有较强的竞争力。在某些特定的应用场景下,mGLM-1B甚至超越了\(mT5_{Large}\)。
XTREME:零样本迁移学习评测基准(Benchmark)
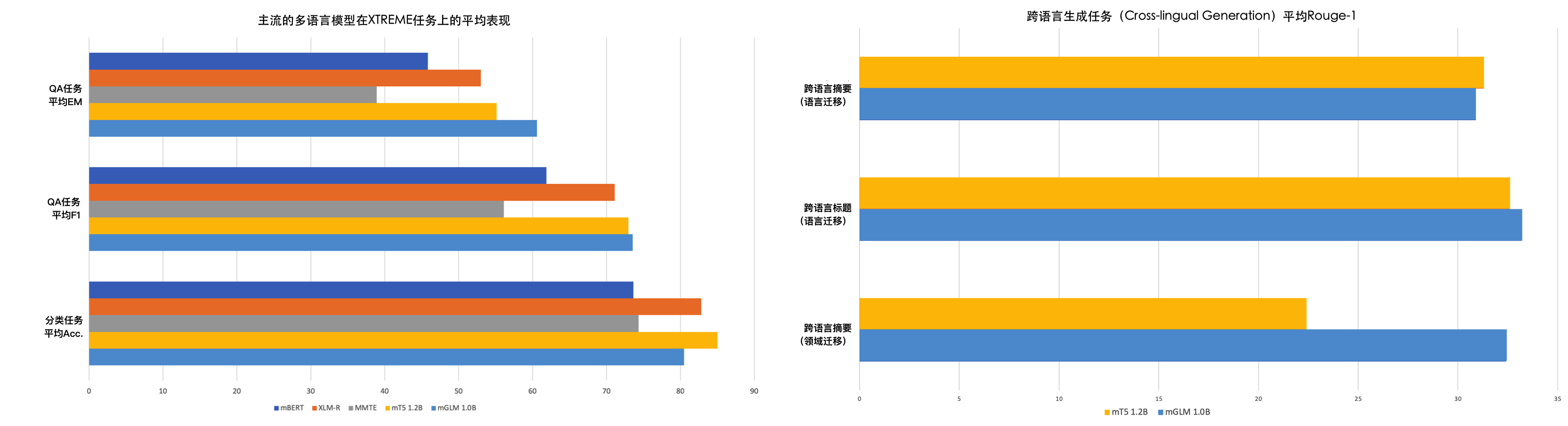
XTREME4是一个知名的零样本迁移学习评测基准。这里我们选择其中的5个零样本学习任务来评估mGLM-1B相比于其它多语言模型的有效性。实验涉及到的多语言模型有mBERT5、XLM-R3、MMTE6和mT52,涉及到的5个评测任务分别是XNLI7、PAWS-X8、XQuAD9、MLQA10和TyDiQA11。这里的XNLI和PAWS-X是多语言句子对关系分类任务,XQuAD、MLQA和TyDiQA是多语言的问答任务。值得注意的是,除了TyDiQA之外,其余所有的评测任务都是基于翻译构建的。TyDiQA则是通过另一种非翻译的方式构建数据:首先由不知道答案的人们提出问题,然后在每个语言的语料中通过问题来检索和收集上下文与答案。
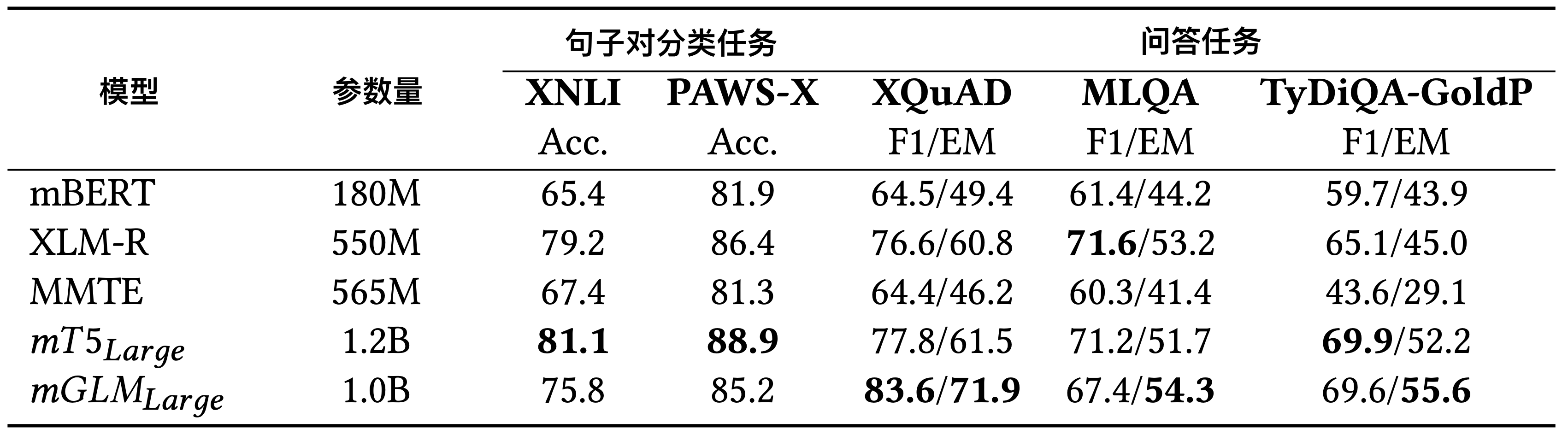
表1中的结果可以从三个方面解读:
- 对于以QA为代表的生成类任务(NLG),\(mGLM_{Large}\)(mGLM-1B) 在同规模的模型中总体表现达到SOTA水平。尤其是在XQuAD任务上的表现,显著超过了包括\(mT5_{Large}\)在内的其它模型。
- 对于以XNLI、PAWS-X为代表的(句子对)分类任务,\(mT5_{Large}\)的表现优于\(mGLM_{Large}\)(mGLM-1B) ,这很可能意味着编码器-解码器框架相比于自回归框架更适合这类NLU任务。
- 即便在某些情况下,\(mGLM_{Large}\)(mGLM-1B) 在F1指标上略逊于同等规模的SOTA模型\(mT5_{Large}\),但在每个任务的完全匹配指标(EM,Exact Matching)上,\(mGLM_{Large}\)(mGLM-1B) 都表现更好。这种现象或许表明,自回归框架比编码器-解码器框架更善于生成连贯和平滑的语言。
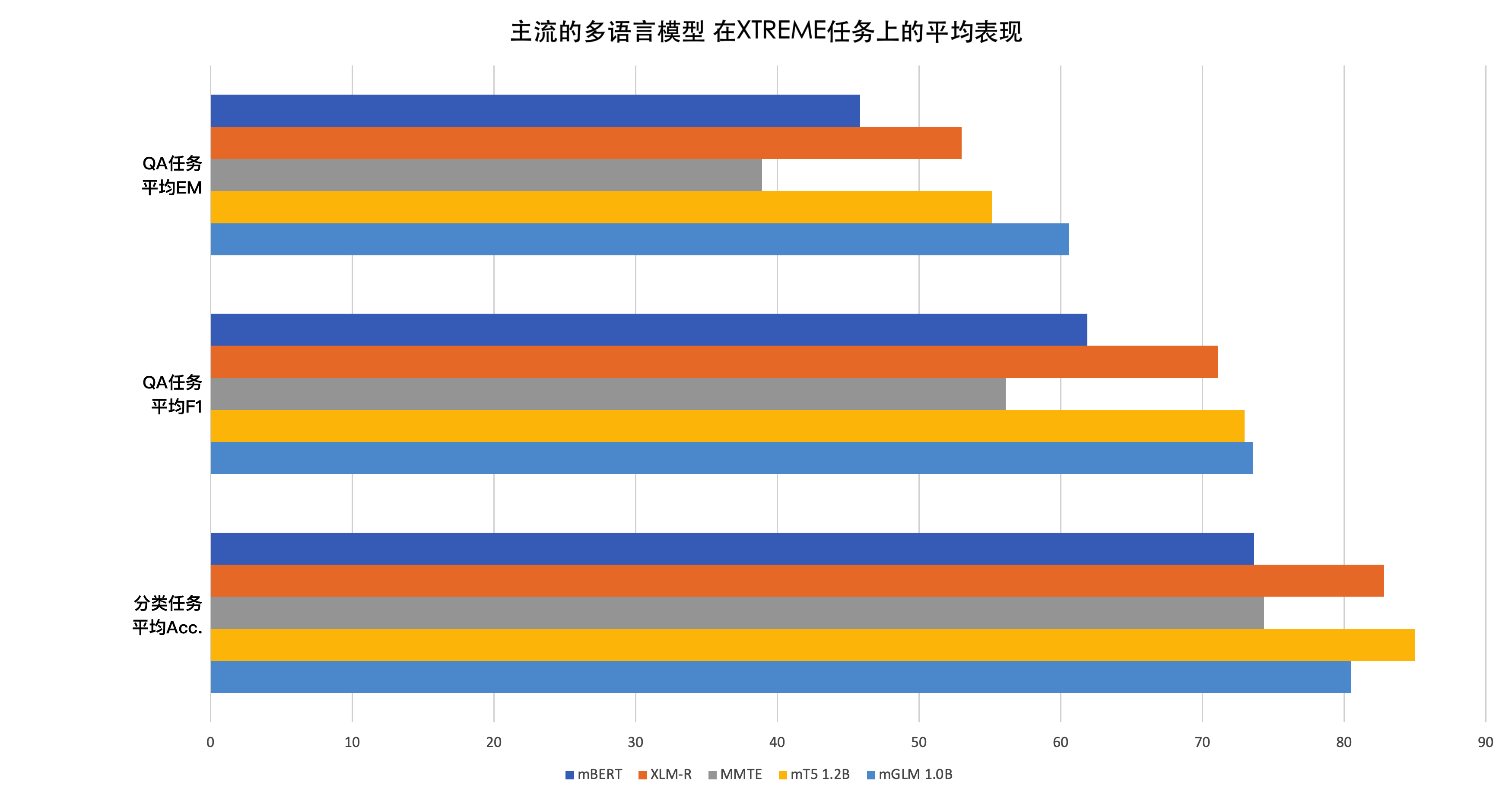
零样本迁移学习:跨语言生成任务
跨语言生成任务可以定义为:在给定一种或多种语言的输入的基础上,根据提示信息生成目标语言的结果。提示词或提示短语会指示需要生成的目标语言,语言模型需要理解输入的多语言信息,并且按照提示信息的要求生成结果。例如:在跨语言摘要任务中,为了生成英语摘要,提示词模板可以写作[source text]. English Summary: [MASK];为了生成中文摘要,提示词模板可以写作[source text]. 中文摘要:[MASK]。输入的源文本信息则可以是任意语言的,模型需要理解提示词的具体要求。
跨语言生成任务也可以测试模型的零样本学习能力。不同的是,此处的零样本学习能力可分为:不同输入语言之间进行零样本迁移学习的能力,以及不同目标语言之间进行零样本迁移学习的能力。需要指出的是,后者往往考验模型的
提示词迁移学习
能力,即模型能否在学习到一种语言的提示词意义之后,将这种能力迁移到指示不同目标语言的提示词上。然而,根据我们的实验发现,目前的语言模型无法完成这类提示词迁移学习。例如,如果我们使用提示词中文摘要:来训练模型生成源文本的中文摘要,它几乎不可能仅仅通过使用新提示词English Summary:就能满足对源文本生成英文摘要的需求。我们将这种现象称作提示词钝性(Prompt
Insensitivity)。因此在跨语言生成任务中,我们往往只能评估模型在不同输入语言之间进行零样本迁移学习的能力。
此处我们评测了两个具体的跨语言生成任务:跨语言摘要生成和跨语言标题生成。在跨语言摘要任务中,模型需要将输入的多语言文章总结为简短的中文摘要;在跨语言标题任务中,模型需要为输入的多语言文章生成中文标题。这两个任务都是零样本迁移任务,即:模型首先在纯英语(或纯法语)文章的数据集上进行微调,然后在不同语言的文章上进行测试。微调和测试的数据集来自MTG12。它是一个近期刚刚发布的、在多语言文本生成任务上的数据集。表2和表3中的结果显示,我们的模型相较于同规模的SOTA模型mT5而言具有较强竞争力。此处的衡量指标为Rouge-1,Rouge-2和Rouge-L。

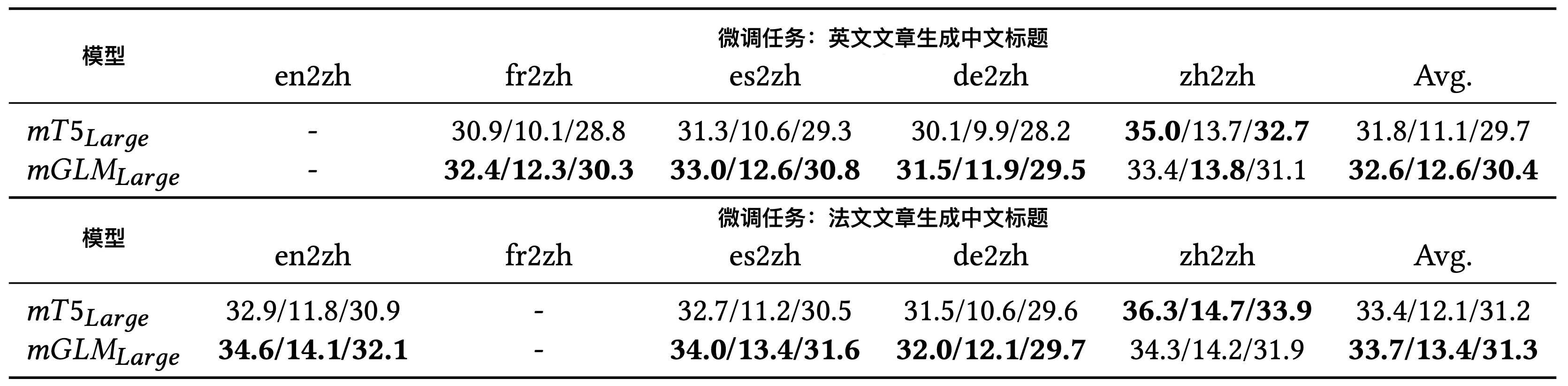
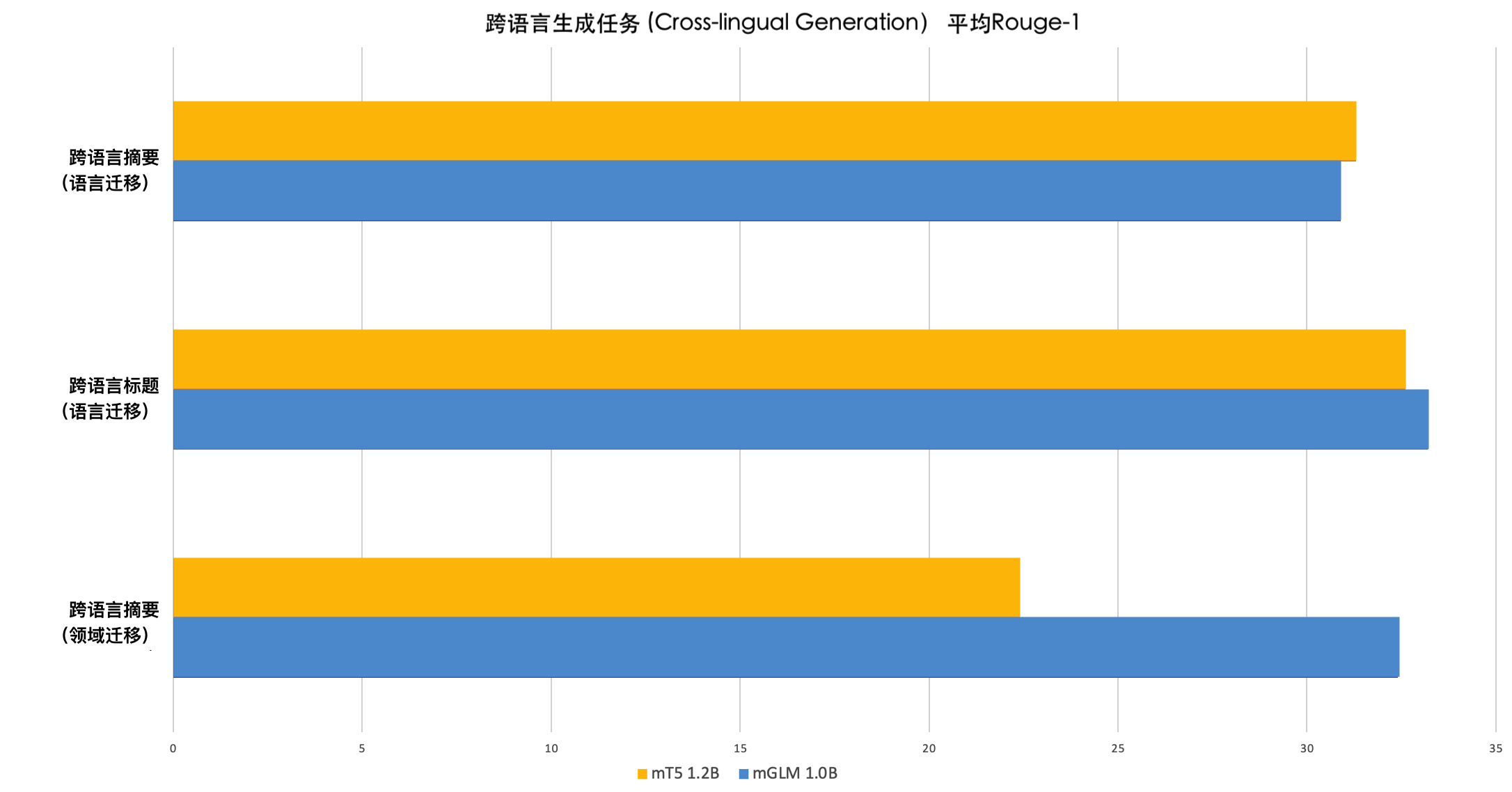
领域迁移学习: 我们同样评测了模型在领域迁移学习方面的能力。此处我们使用的微调数据集为NCLS En2ZhSum13,它是一个新闻领域跨语言摘要的数据集(原文为英语,目标摘要为中文);我们使用的测试数据集为Scisummnet-zh,它来自于Scisummnet14——一个学术领域的英文摘要数据集,我们将它的摘要通过机器翻译生成了中文的结果,并由此构建了学术领域的跨语言摘要数据集Scisummnet-zh。实验结果显示,我们的\(mGLM_{Large}\)(mGLM-1B) 模型表现超过了同规模的SOTA模型$mT5_{Large}$。这表示mGLM-1B可能具有更好的领域迁移能力。

mGLM-1B: 模型
mGLM-1B模型基于通用语言模型(GLM)框架,同样使用自回归空白填充任务作为其预训练目标。我们会随机遮盖连续的文本片段,并训练模型通过自回归的方式重构它们。
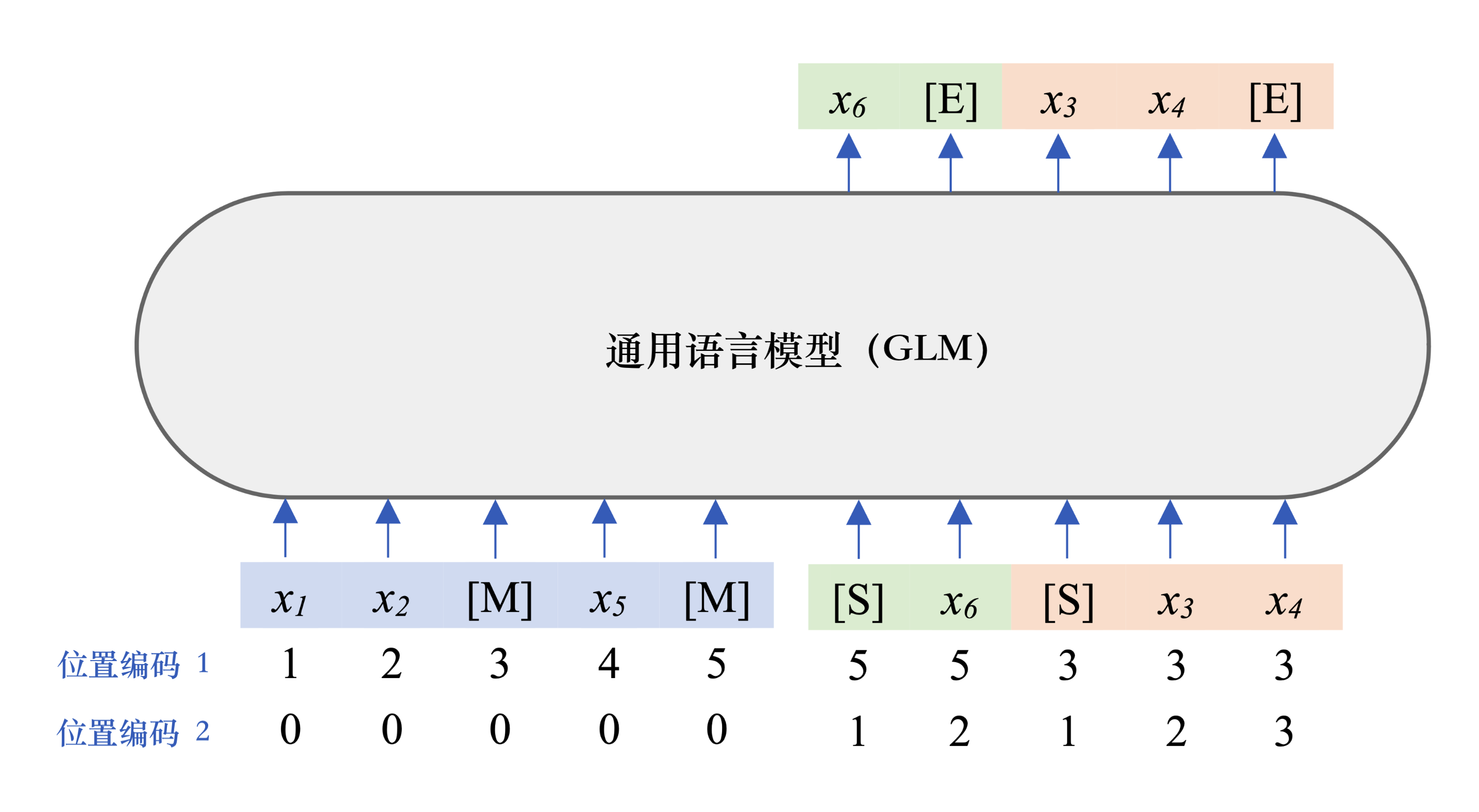
图5展示了GLM预训练框架是如何工作的:模型总是按照从左到右的方式来生成每一个单词。为了区分生成的单词是否属于同一个被遮盖的片段,GLM引入了2D位置编码,通过编码片段号和片段内的连续位置关系来表示单词的确切位置。GLM框架还支持多任务训练,模型在预训练过程中会同时学习句子级别和文档级别的生成,我们通过遮盖更长的片段来实现构造文档级别的样本。预训练的过程中样本的遮盖比例设为15%,遮盖片段的长度随机选取,句子级别的样本遮盖长度的选取服从泊松分布;文档级别的样本遮盖长度的选取服从均匀分布。
mGLM-1B的代码实现基于SwissArmyTransformer(或称 SAT)15。SAT是一个用于开发各类Transformer变体的易扩展Python库。我们使用Deepspeed16完成多节点间的分布式训练。
应用场景:跨语言摘要
我们可以基于预训练的多语言模型快速开发跨语言应用。通常只需要一个在双语数据上的微调过程,就可以让多语言模型通过自身的零样本迁移学习能力支持多种语言的输入。我们基于mGLM-1B开发了一个跨语言摘要工具,它可以将任意语言的文章总结成简洁的中文摘要。为了让模型达到最好的效果,微调阶段我们混合了NCLS En2ZhSum13和翻译过的SCITLDR17数据集。结果显示该工具在新闻、学术、百科文章等多个领域均有不错表现。我们最终将这个跨语言摘要工具制作成了一个Web Demo18和AMiner网站19上的一项功能:论文概述。
未来工作
本项目的研发还在继续进行中。我们将会继续进行更多的自然语言生成任务(NLG)实验,例如MTG12中的另外两个任务——故事续写以及问题生成。我们将会开源更多的下游任务微调代码。此外,我们也计划发布更大的、或推理更高效的模型。除了mGLM和mT5,我们也将复现其它的多语言模型,例如mBERT、mBART和XLM-R等,从而得到一个更加全面完整的多语言模型比较结果。欢迎开源社区的使用者和开发者加入我们,一起推动mGLM的发展。
相关链接
跨语言摘要微信小程序

-
Du, Zhengxiao, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. “GLM: General Language Model Pretraining with Autoregressive Blank Infilling.” In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 320-335. 2022. ↩︎
-
Xue, Linting, et al. “mT5: A massively multilingual pre-trained text-to-text transformer.” arXiv preprint arXiv:2010.11934 (2020). ↩︎
-
Conneau, Alexis, et al. “Unsupervised cross-lingual representation learning at scale.” arXiv preprint arXiv:1911.02116 (2019). ↩︎
-
Hu, Junjie, et al. “Xtreme: A massively multilingual multi-task benchmark for evaluating cross-lingual generalisation.” International Conference on Machine Learning. PMLR, 2020. ↩︎
-
https://github.com/google-research/bert/blob/master/multilingual.md ↩︎
-
Arivazhagan, Naveen, et al. “Massively multilingual neural machine translation in the wild: Findings and challenges.” arXiv preprint arXiv:1907.05019 (2019). ↩︎
-
Conneau, Alexis, et al. “XNLI: Evaluating cross-lingual sentence representations.” arXiv preprint arXiv:1809.05053 (2018). ↩︎
-
Yang, Yinfei, et al. “PAWS-X: A cross-lingual adversarial dataset for paraphrase identification.” arXiv preprint arXiv:1908.11828 (2019). ↩︎
-
Artetxe, Mikel, Sebastian Ruder, and Dani Yogatama. “On the cross-lingual transferability of monolingual representations.” arXiv preprint arXiv:1910.11856 (2019). ↩︎
-
Lewis, Patrick, et al. “MLQA: Evaluating cross-lingual extractive question answering.” arXiv preprint arXiv:1910.07475 (2019). ↩︎
-
Clark, Jonathan H., et al. “TyDi QA: A benchmark for information-seeking question answering in typologically diverse languages.” Transactions of the Association for Computational Linguistics 8 (2020): 454-470. ↩︎
-
Chen, Yiran, et al. “MTG: A Benchmark Suite for Multilingual Text Generation.” Findings of the Association for Computational Linguistics: NAACL 2022. 2022. ↩︎
-
Zhu, Junnan, et al. “NCLS: Neural cross-lingual summarization.” arXiv preprint arXiv:1909.00156 (2019). ↩︎
-
Yasunaga, Michihiro, et al. “Scisummnet: A large annotated corpus and content-impact models for scientific paper summarization with citation networks.” Proceedings of the AAAI conference on artificial intelligence. Vol. 33. No. 01. 2019. ↩︎
-
Rasley, Jeff, et al. “Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters.” Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020. ↩︎
-
Cachola, Isabel, et al. “TLDR: Extreme summarization of scientific documents.” arXiv preprint arXiv:2004.15011 (2020). ↩︎